Start Controlling Your Email Deliverability.
When email performance impacts revenue, retention, or security, you need more than an API endpoint.




Deliverability problems rarely come from a single setting. They come from:

Mixed traffic (transactional + marketing) sharing the same reputation

Shared IP pools and unpredictable neighbor behavior

Limited routing and retry control when ISPs throttle or degrade

Lack of message-level visibility when something goes wrong
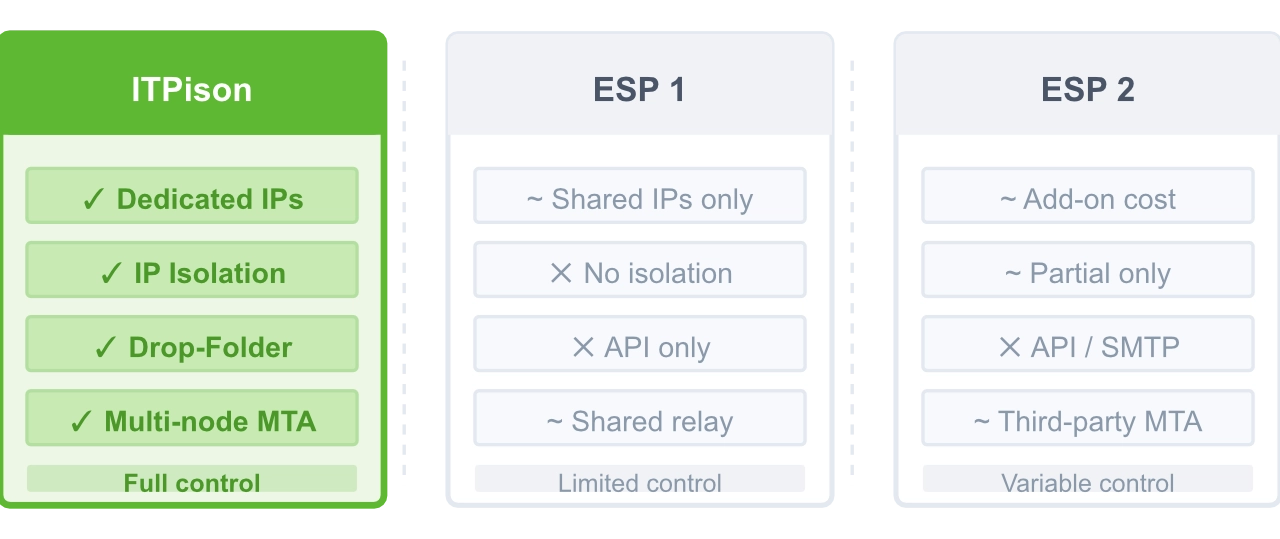
You don’t really control deliverability
A) Your product email and marketing email compete for reputation
Password resets and receipts must land instantly—but campaign spikes can poison your reputation.
What teams need:
Separate streams, isolated IP pools, and predictable throughput.
B) You operate multiple brands, tenants, or business units
One brand’s list quality shouldn’t affect another.
What teams need:
Segmented environments and infrastructure isolation.
C) You’re accountable for compliance, auditability, and incident response
When a delivery incident happens, “we think it was throttled” is not good enough.
What teams need:
Message-level logs, routing traces, and operational visibility.
D) You send “high-risk” internal emails that trigger filters (security drills, training, IT notices)
Your organization may run internal security simulations (e.g., phishing-awareness exercises) to reduce social engineering risk. These sends are uniquely sensitive: they often resemble real attacks, triggering filtering and reputation concerns if not isolated properly.
What teams need:
A segregated environment with strict controls and clear audit trails.
E) Large attachments cause non-delivery and degraded inbox placement
Bounces and filtering can spike when payloads are too large or inconsistent.
What teams need:
Delivery-safe workflows (e.g., attachment handling strategies) and reliable routing.
Dedicated Infrastructure (No Shared Reputation Risk)
• Dedicated IP pools
• Segmented sending environments by traffic type, tenant, or brand
• Reduced reputation contamination across streams
Business result: fewer “mystery dips,” safer scaling, faster recovery.
Observability Built for Operators
Deliverability control requires visibility. ITPison emphasizes:
• Message-level logs
• Delivery insights (bounces, retries, outcomes)
• Operational signals for diagnosing issues fast
Business result: faster root cause, better decision-making, less guesswork.

Dynamic Failover Routing
When a route, node, or IP degrades, ITPison can reroute automatically to maintain delivery continuity.
Business result: fewer delivery incidents, fewer all-hands escalations.

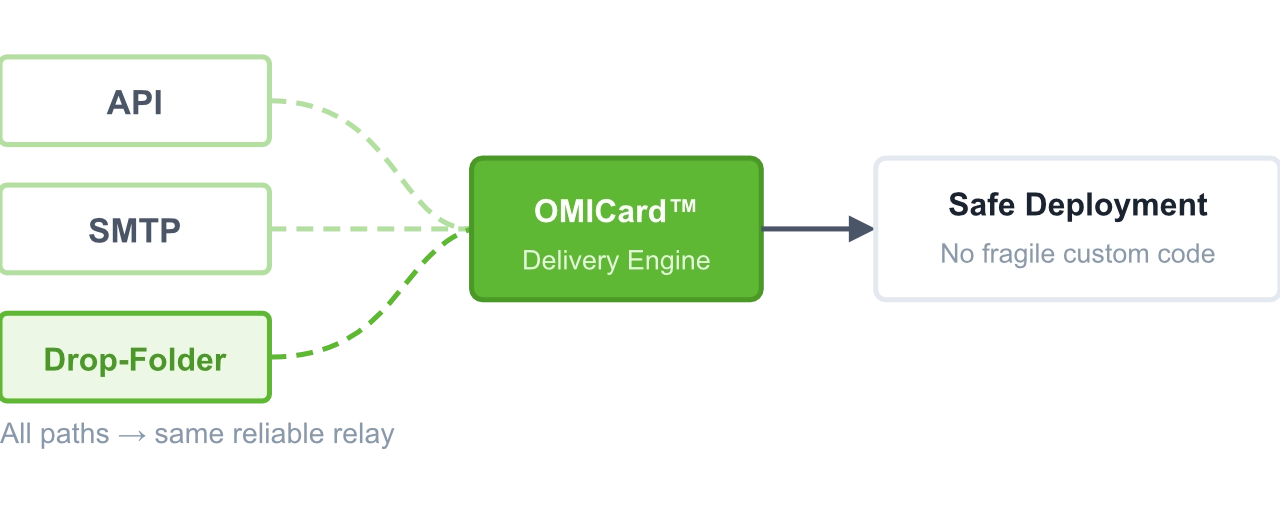
Integration Flexibility (Prevents “Implementation Deliverability Debt”)
• API for modern systems
• SMTP for compatibility
• Drop-Folder for legacy/no-code pipelines
→ reduces fragile custom code and speeds up safe deployment

Reputation Isolation
• Dedicated IP pools
• Segmented environments (transactional vs marketing, tenant vs tenant, brand vs brand)
Resilience + Routing Control
• Multi-node architecture
• Dynamic failover routing for degraded paths

Operational Visibility
• Delivery logs and insights
• Traceability for support and compliance workflows
Deliverability control isn’t only technical—it’s operational.
ITPison has deep experience supporting enterprise-grade workflows that require:
Directory integration patterns (e.g., LDAP-based org structures) for managing access and governance.
Engagement tracking and reporting for controlled internal programs (e.g., security training simulations).

Delivery-safe workflows that reduce “avoidable failures” (e.g., attachment size handling patterns).

Send auditing (who sent what, when, and why).
Get Deliverability Control You Can Operate
Deliverability problems don’t fix themselves. If yours affects revenue, brand, or security — your team deserves real infrastructure control, not workaround tips.
(Ask for a deliverability architecture review: segmentation + dedicated IP strategy + routing resilience.)